近期中研院運用了一個名為Llama-2-7b的模型來對兩個資料集:COIG-PC和dolly-15k進行微調,但由於這些資料都是簡體中文,因此在上線時引發了不少烏龍事件,我相信大家對此並不陌生。然而我們對於模型究竟做了哪些事情,以及為何有人將其稱為ChatGPT的本地端?它和ChatGPT有何關聯性?都非常不了解,因此今天要來深入探討這個模型的運作原理,今天的學習重點如下:
LLaMA 1與LLaMA 2的理解LLaMA RLHF計算方式LLaMA(Large Language Model Meta AI)是Meta AI公司於2023年2月推出的大型語言模型,因其開源的特性與其擁有ChatGPT相似的效能,使得該模型受到許多人喜愛,所以許多人會加以微調以達成預定的目的,甚至有許多人將這種模型視為「本地端ChatGPT」或「開源ChatGPT」。
令人驚訝的是儘管LLaMA的參數量較少,卻能完成通常需要更多模型參數的任務,根據開發團隊的報告LLaMA-13b在大多數的基準測試中,其表現甚至超越了擁有17.5B參數的GPT-3,現在我們來看看下圖中有關於該模型性能的詳細資訊。
圖片來源:How Does Llama-2 Compare to GPT-4/3.5 and Other AI Language Models
圖中主要展示了LLaMA的各種能力,特別是在MMLU與AGIEval兩個測試語意理解程度的資料集上,Llama-2-70B表現出眾,其效能甚至遠超乎同類參數量的Llama-1-65B和其他兩種大型語言模型。在TriviaQA這個測試集上,Llama-2-70B的性能更是達到了85%。
除此之外該模型在Winogrande常識推理資料集和BoolQ邏輯判斷資料集上的表現也十分出色,這使我們認為LLaMA 1與LLaMA 2都是具有強大推理能力的語言模型,眾多研究結果進一步指出Llama-2-70B的模型能力已足以超越gpt-35-turbo(0317)版本,因此它甚至被視為目前SOTA模型GPT-4的挑戰者。
該模型與ChatGPT、PaLM、Chinchilla等大型語言模型最主要的不同之處,就是在它的完全開源的特性。這種設計讓我們可以自行運用和調整該模型的權重,打造出更專精的語言模型。同時也能隨時增添新的資料以優化模型。在所有的開源模型之中,該模型是目前唯一一個採用RLHF訓練的因此在生成能力與穩定性也能夠超出其他的大型模型,此外ChatGPT不同的是該模型並未設置太多的道德限制,雖然這雙刃的特性一方面能提升特定行業的效率,但在另一方面也可能引發社會風險。
相較於OpenAI,LLaMA在訓練階段時使用的數據也開放,它使用了CommonCrawl、C4、Github、Wikipedia、ArXiv、StackExchange等資料作為訓練資源,其中CommonCrawl和C4的資料占了訓練資料的80%,主要是用來培養模型理解和回答問題的能力。同時Github和StackExchange的資料被用來訓練它的程式撰寫能力,ArXiv和Wikipedia的資料則用於培養它的學術研究能力,並且訓練時的這些資料都是開源的資料集,也就是說只要硬體設備充足,我們就可以復現這個實驗。
而LLaMA之所以能用更少的參數來實現更高參數量的模型所能達成的功能,主要是因為他改善了一些大型語言模型的缺點,而改良的第一步就是針對Transformer中的每一層進行正規化,而非只對Transformer的輸出進行正規化。並且在這個步驟中LayerNorm的公式中的平均值被認為是不必要的,而是只需要模型保留標準差作為正規化後的特徵,就能夠有更好的性能,這點在實驗中也被證實,因此它修改了LayerNorm成了RMSNorm來解決這項問題。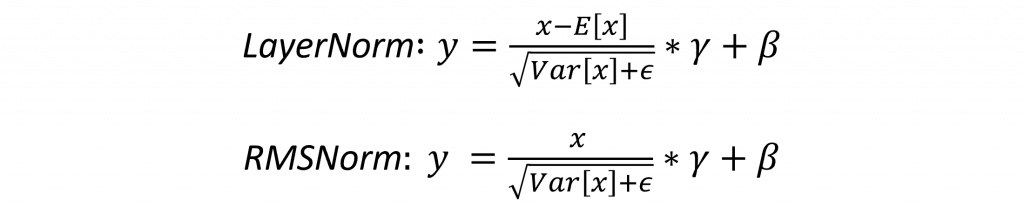
在Transformer的feed-forward層中是使用了ReLU作為激勵函數,但我們從【Day 12】該如何選擇損 失函數與激勵函數?中文該如何斷詞?這篇文章中知道了若使用ReLU會有可能發生神經元死亡的問題。
因此為了解決這個問題,LLaMA在這裡選擇使用了SwiGLU這是ReLU的一種變化,它能給予負值區間的數值一定的適應性這讓它與feed-forward層更為匹配,這是因為經過RMSNorm處理後的數值已經趨近穩定,所以如果這裡的負值太高,就該進行截斷處理以防止在更深的層中導致資料發散。
並且由於Positoinal Embedding的編碼方式還不夠完善,因此在LLaMA中便採用了旋轉位置編碼(Rotary Embeddings)的方法,這種方法能嘗試將位置資訊與資料內容融合,以便更好地適應各種不同的任務和資料類型,該方式採用數學中的極座標系統表示位置資訊,將位置資訊編碼為複數,其中複數的長度表示了位置的距離,而複數的負角則表示了位置在複數平面上的方向,因此這種表達方式的特性能夠被Multi-Head Attention更好地計算,使其生成的向量具有更高的結構性。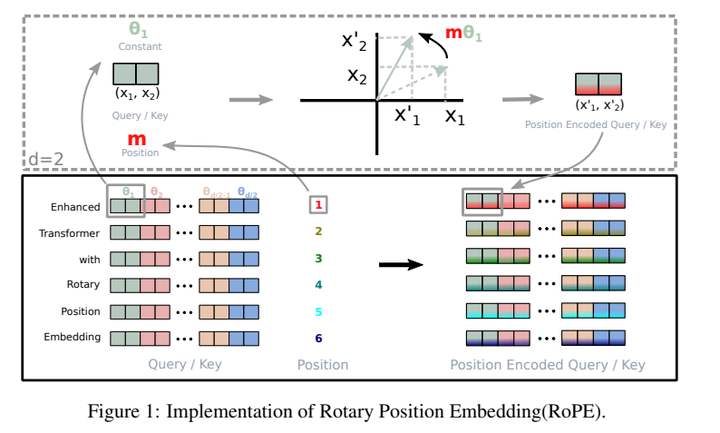
另外對於傳統的Multi-head Attention其需計算q、k、v向量,進而需求更多的記憶體,而為了提升訓練效率,該模型採用了Grouped-query Attention的方式,讓所有head能共享k、V矩陣,而根據作者們的根據實驗結果,兩者在效能上的差異並不顯著,因此在這選擇了Grouped-query Attention來增加模型的速度
這個模型採用了以小模型大數據的方式進行訓練,這種方式能夠讓模型更充分地吸收資料的內容,然而這種方法需要謹慎考慮模型的結構設計。基於這個原因LLaMA對基礎Transformer進行了上述三個改動目的是優化模型在收斂過程中的表現。而在LLaMA 2中還以此為基準添加了一個RLHF機制進行模型調整。
最後我們使用RLHF的方式對該模型進行調整,使其能更好地遵循人類偏好(Human Preferences)和遵循指令(Instruction Following)這兩個目標,在這個過程中我們利用獎勵機制和懲罰機制來對模型進行調適。我們首先讓模型產生一次文本,接著通過人工比對找出最佳的生成結果。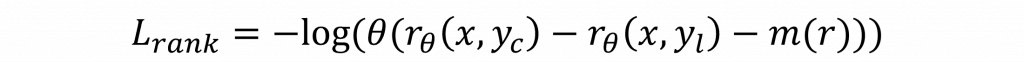
在LLaMA 2中對於RLHF的損失函數的計算方式是先透過𝑟𝜃 (𝑥,𝑦)來計算分數,其中yc代表正面的回覆,yr則代表負面的回覆,而x是首先設立的Instruction,然而在訓練過程中,評分方式是將分數訓練成四個階級,這相對於二元分類使得收斂更為困難,為了解決這個問題,所以設計了一個m(r)的離散函數以穩定生成結果。
同時我們希望該模型不僅有用,也能保證安全性,然而這裡可能存在著訊息有用但不安全的狀況,因此對於RLHF的評分,我們需要建立兩個不同的評估模型。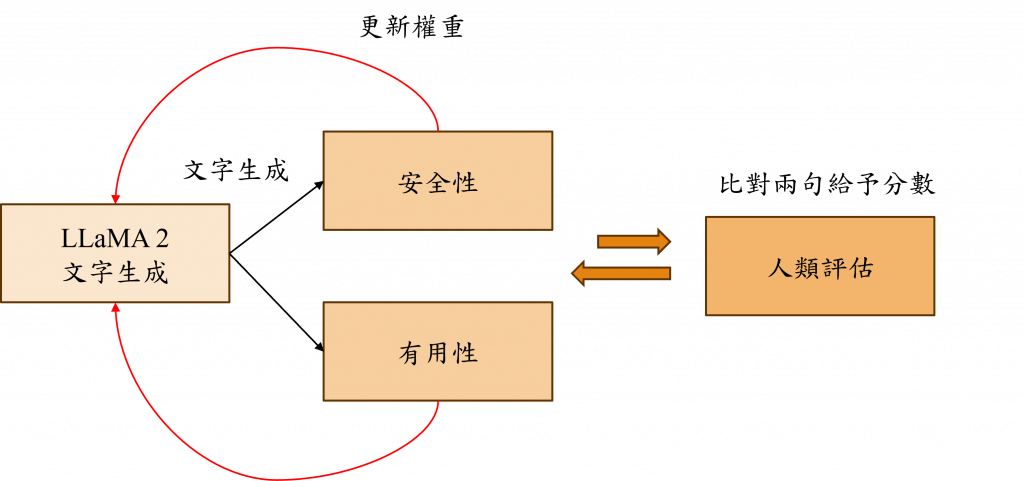
這樣子我們就能夠根據人類的反饋來調整模型之間的權重使其更安全更有用。
今天你應該已經理解了LLaMA的優點以及實現方式,而這個模型也代表了目前自然語言處理的最新進展,並且在這種開源模型的推動下,自然語言處理與模型改進的速度大幅提升。現在LLaMA正與GPT-4爭奪SOTA模型的榮譽。而對於企業來說,這種開源的大型模型更能提供彈性調整以達到他們的需求,我相信在不久的將來可能會有更多微調版本的LLaMA出現,足以將GPT-4挑戰下神壇,所以明天我將會教你你如何用Pytorch進行RLHF與微調的操作。
那麼我們明天再見!
內容中的程式碼都能從我的GitHub上取得:
https://github.com/AUSTIN2526/iThome2023-learn-NLP-in-30-days


 iThome鐵人賽
iThome鐵人賽